

When it comes to mastering, Bob Katz is probably the engineer's engineer. Besides his mastering work — with credits like Cassandra Wilson and Sinéad O'Connor — he's written several books on the subject matter, invented the K-Stereo system to address details in a mix, and has developed a scale for equal monitoring volume. Bob took the time to explain his concepts, predict the end of the loudness craze, and promote a petition for streaming services to implement normalization by default.
What is the current state of the loudness war? Judging from the coverage of this topic — and the public backlash against extreme records — one is likely to believe that most artists are aware of this issue by now.
Well, an increasing percentage of artists know about it — around 20 to 40 percent — but many are completely unaware. I don't think there will ever be more than that, because most people are not even the least bit technically inclined. Just the other day I did a master, and there was so much ignorance — it came down to a loudness comparison. That discussion will simply continue to take place, because there are people who work in their own music world who don't read magazines or books, or produce recordings.
What would be a solution?
The solution has to be external to that. The compact disc has to die in order for it to happen. I'm sorry! [laughs] I'm really very sorry about that. Digital downloads have to take over completely. Because whatever software is used for reproduction should have transparent normalization, which would take place behind the scenes. As of this moment, there are no good implementations in consumer software, except for a product called JRiver; an audiophile-grade audio and video player that works on both Mac and PC. But until the major player, iTunes, actually implements this process as a default, there won't be much movement. It will happen eventually, but they don't tell us about their plans. They know it has to happen. Apple had already implemented their Sound Check normalization algorithm by default in their streaming service, iTunes Radio, but that service has been abandoned. Spotify uses too high a target and adds peak limiting. Normalization is made optional. Tidal has just begun to normalize their service with a sensible target of -18 LUFS, bless their hearts. I was part of a group of audio engineers, spearheaded by Thomas Lund and Eelco Grimm [of the Music Loudness Alliance], that managed to convince Tidal to normalize. This was not too difficult, inasmuch as Tidal has always been proud of its audio quality. The level is well within the AES Streaming loudness recommendations, whose committee I headed. This is a big development — Apple may not be long to follow. YouTube normalizes too high, to —13 dB. So the landscape has not gotten much better, post compact disc. There's a petition at change.org, which I participated in writing and promoting https://www.change.org/p/music-streaming-services-bring-peace-to-the-loudness-war. We have over 5000 signatures. We hope to get even more, so as to influence the streaming vendors to implement normalization by default. With iTunes Radio, we've seen the light at the end of the tunnel, and it's been the first light that we have seen in 40 years! Radio has to be normalized anyway, there's no question. It's just that iTunes Radio didn't process the audio; all they did was normalize the audio. We could quibble about iTunes using AAC encoding, not pure PCM, and so on; but this is still a big step, because most people use AAC in iTunes. Engineers make it sound — shall we say — pretty good. With normalized playback, producers are no longer going to ignore the fact that they can't push their music without any consequences. I'm hoping that even in the car, people will play iPods and iPhones for sound, and the Sound Check algorithm will be activated by default.
Part of the mastering job is to relate the song levels to each other in the course of an album. This relationship would be destroyed if every song gets normalized on its own, and not within the context of its album. Does Apple's Sound Check use an overall album normalization value?
I figured out exactly how the Sound Check album algorithm works a few weeks ago by various tests. It is clear that Apple does not store an album normalization value anywhere as an explicit number or metadata. Instead, it calculates the album normalization based on its database of all the songs that are in that album that it knows about. If the whole album is already in the user's database, or if the loudest song from the album is already in its database, then Sound Check album mode will work correctly. What it does is use the same Sound Check normalization gain for the loudest song for all the songs in that album. Once you know the loudest song, then you can play all the songs from that album correctly.
Has the renaissance of vinyl helped constrain the loudness idea in the business?
Yes, vinyl helped that. But you'd be surprised how many vinyl records are made from super-compressed masters because of the cost factor to master two different versions. That might take a day and a half, instead of a day. That's expensive for the artist. If we want to do it right I could easily take my good master and smash it then, but it doesn't sound as good as if I started working from the beginning with the intent of making a hot master, because there are two different philosophies. As a general rule, the more compression you apply, the duller it sounds in the high-end. Of course, there are compressors which sound brighter, but usually the high-end tends to go down because the transients are softened. You can't get away without changing the EQ.
Regarding monitoring and volume: In movie theaters there's the standard of 83 dB SPL — or 85, depending on how it is measured — since the 1980s. This turned out to be pleasant for the biggest part of the audience. In audio there is no common standard, which makes it hard to judge material because of Fletcher-Munson inadequacies.
I'm advocating a monitoring calibration that's based on that. My system of calibrated monitoring is finally recognized enough so that more and more people are coming to it. It's even more important because of loudness-normalized media. The magic number in film is 85 dB. But measured how? RMS [Root-Mean-Square]? What kind of pink noise? It's a fudge, because if you measure it in a different way, you can get 83. You have to go with 85 if you use the SMPTE standard. You go with 83 if you use the RMS standard, which I'm advocating. Then you don't have to use proprietary Dolby equipment for audio monitoring.
Regarding the film standard — how did they come up with that number in the first place?
The person who came up with 85 was Ioan Allen of Dolby. He actually pulled the number out of thin air. He said, "Well, it's about in the middle of the Fletcher-Muson Curve. This would be a good number to go for, because it would make the most linear masters." And it's proved the test of time.
For working with music and film you've defined two scales; K-14 and K-20. How did you make the analogy to music?
What made me have the big realization of what was going on in my mastering was that I began to use a calibrated monitor attenuator that I built, with a 1 dB per step potentiometer — an analog attenuator. I was mastering and measured the SPL, and it was about 83. I was also using a K-14 scale, which is showing up. The K-20 scale, which is 6 dB below, puts you in film world. I said, "All I'm doing in mastering is working to a higher RMS level, but keeping the same sound pressure level as the film people." So I said, "Why don't we just have a moveable scale that reflects what the two worlds are doing?" That would mean you have to adjust your monitor control, too. Let's say the K-14 scale makes a great sounding master. If you decide, "I'm going to make sound for a film, and I have to work to their standard," you would change your scale and come down 6 dB. When the needle is now at 0, it would be at -6 dB, and that would be called 0 dB then. But in order to hear that properly, you have to turn your monitor up 6 dB. In other words: to play back a theatrical film, which has a lower program level, you have to turn your monitor up, compared to music. So I said, "Why don't we equate the monitor gain with the program level?" That's what hit me. I created a system where you have a monitor set at 0 dB. The monitor gain will produce 83 dB SPL with calibrated pink noise — all measured at the listening position, per speaker, RMS. These days I recommend the pink noise that Tom Holman [Lucasfilm/Apple] has recommended. If you're doing music for contemporary productions made today in the pop field, you'll have to attenuate that monitor — or it will blow you out of the room! The higher you make your zero point, it's likely the material will be more compressed, so if you turn your master up 6 dB it will not sound exactly 6 dB louder. It could be softer and sound wimpy, as there is a point of no return. For "typical" pop music, that is somewhere around -14 LUFS. But there is no rule, I make many great sounding masters and many better sounding at lower levels, and occasionally higher levels. That's what's so hard to communicate to producers, that once the best sounding master has been made, the best way to get good sound is for the listener to turn it up. When normalization becomes a default for the streamers, it will be much easier to communicate that.
Let's look at a common example of a smashed record, The Red Hot Chili Peppers' Californication. How would the playback volume need to be adjusted to play at equal loudness?
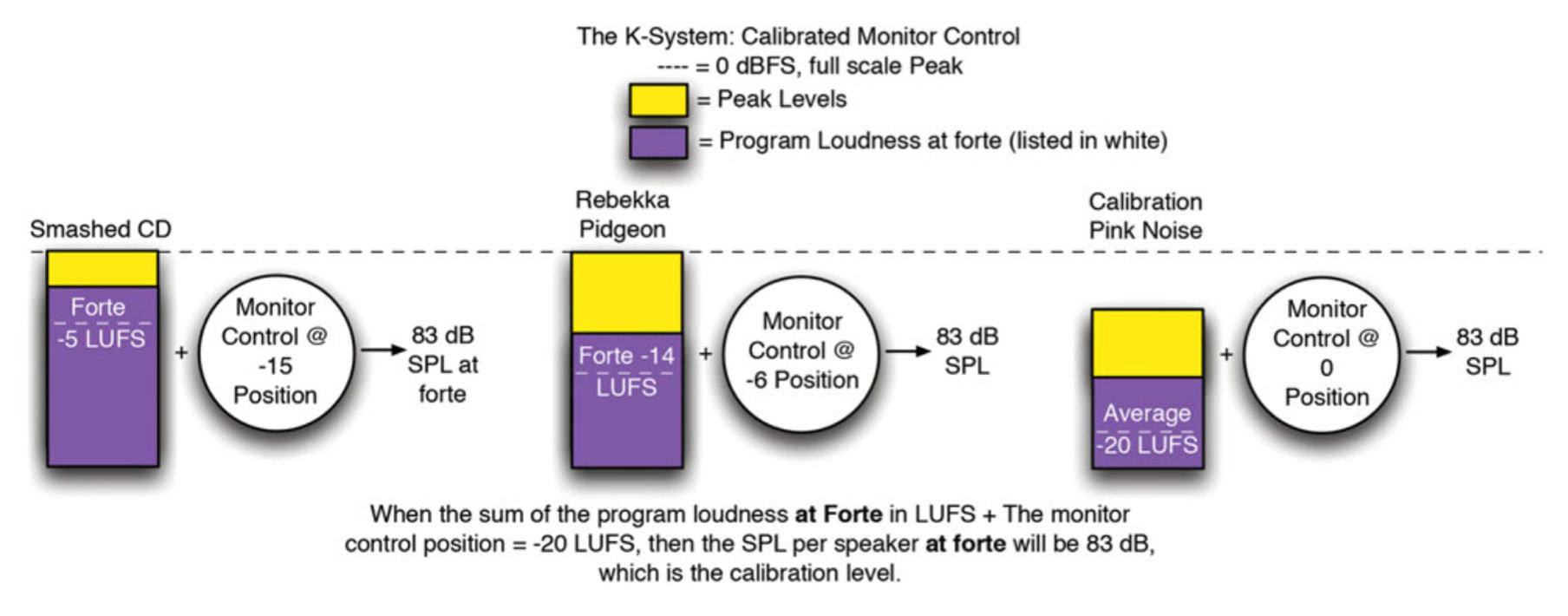
The Californication record plays at -15 dB on that monitor gain control! If you have a calibrated monitor, you know exactly how loud it is in program. The K-System refers to the "control position" of the monitor. For example, we can say, "The monitor control is at the 0 dB position." This is the calibration position, which will produce 83 dB SPL per speaker with the calibration signal. We should think of the monitor control like a water faucet. The more pressure there is in the water pipe, the more we have to close the faucet to get the same water pressure. A smashed CD has tremendous internal pressure; it has high program level and very low peak-to-loudness-ratio. Looking at the graph we can learn how the system works and how useful it can be: at left is a smashed CD with a very high average loudness of -5 LUFS [Loudness Units relative to Full Scale, in practice the same as the RMS level]. Its PLR [peak to loudness ratio] is only 5 dB! We have to lower the monitor control to the -15 position to get out 83 dB SPL, and that will probably still sound extra loud because of the distortion in this CD. In the middle is Rebekka Pidgeon's Spanish Harlem recording on Chesky Records. This is a true K-14 recording that sounds lovely with the monitor control at the -6 position. At right we see the calibration signal. Very few compact discs are at this level. In other words, by observing the monitor control position, we can make conclusions as to the program loudness and the "peak to loudness ratio" of the recording we are listening to — assuming that the recording is percussive and has been peak-normalized. When we move to normalized media, such as iTunes with Sound Check, the goal is to reproduce everything at the same loudness. So it's possible the monitor control will not have to be moved, except for personal or genre preferences. In other words, we like electric rock to sound louder, so we'll have to turn it up a bit more than the folk music, but that's a small price to pay for sound quality. Still, the monitor will not have to be moved more than, say, 3 dB, to satisfy every taste on earth!
With the K-System, since the 83 dB is measured per speaker, as a result, that would lead to a higher SPL in total with both speakers summing up at the ear, right? 86 dB then?
That's correct, but don't worry about it. The calibration is done on a per speaker basis, and the rest happens naturally. Yes, it would be 86 dB with uncorrelated — channel to channel — pink noise. I have a sample of both channels, full range, uncorrelated pink noise at www.digido.com. You check that noise just to see how well matched your loudspeakers are, because if they only add up to, say, 84, then your loudspeakers are not well-matched in frequency response, sensitivity, and phase. But don't use the 86 as a number to align with, use the 83 per speaker. Then we can extend this to surround and keep to the standard. By using the individual speaker level for calibration, as we expand to 5.1 from stereo we gain headroom, not lose it.
Also, I noticed that some people understand the calibration and the 83 dB the wrong way, and listen much too loud in the end. Where do they go wrong?
The first thing to note is that K-System levels at forte will seem loud if the loudspeakers are not in the midfield and/or they do not have good headroom. I was in a friend's living room the other day with an ordinary 5.1 system with rather small speakers and amplifiers. He had to align his system to 77 dB per speaker with the calibration signal, or it would sound too loud. I agreed. K-System is very comfortable and not damaging in my room because the loudspeakers do not distort and they are far enough away to mitigate extreme transients. So the K-system calibration is designed for engineers with a "mastering quality" loudspeaker system located in the midfield. If your amplifier-speaker combination distorts at high levels. If your loudspeakers are too close, then it will not sound very good when played loud! And it might damage your ears over time, just because of the ear fatigue. Not to say that I play my system that loud all the time when I'm mastering highly-compressed material, because it sits at forte for too long a time and sounds fatiguing. But dynamic material played at 83 dB per speaker at forte sounds just fine and does not damage the ears, in my opinion, with these occasional bursts to forte.
Let's look at the "underrated" jobs of a mastering engineer. According to your book, Mastering Audio, the gap between songs and its contribution to an album's flow is often overlooked. What difference can the right gap make — and what is often done incorrectly?
The first thing that can be done wrong when delivering the mixes is not to listen to the songs in a quiet room, because the decays at the end of the songs are very important. Just yesterday, the client was very embarrassed when I showed him that he'd cut off the end decay of a song. He said, "I mustn't have heard that." The point I make to mixing engineers is not to assume the song has already ended. It's always better to send the songs off to a mastering engineer with what we call handles — at the head and the tail, at least a second, preferably two or three seconds. Then we're sure that you've given us everything that you need to give us. Then, when we determine the gap, we have to take that decay into account. Sometimes, there may only be a quarter second space between this long decay and the beginning of the next song. The average listener will think that the decay was only a couple of seconds, but the decay might be four seconds! That's because they're listening in the car, or in a noisy environment. In a quiet environment you will hear the whole decay; there's only a tiny space and then the next song begins, and it sounds just right to you. But the average person thinks there is a space there, and that works out too! So, the spacing is important to be done by an experienced person in a quiet environment who also checks it in a noisy environment. A space that seems short on headphones can seem really long in a car or in a noisy environment. Also, aesthetically, if you're in transition between a slow song and a fast song, you wouldn't want to make a short space. Chances are the ears would be startled by the sudden downbeat. But if you're creating a set of three fast songs in a row, you probably want the pace from each song to the next to be pretty fast, so that you don't lose the groove.
What are gaps worth, in terms of downloads or when copying CDs into your computer library?
Gaps still exist. The solution with iTunes is quite simple: all songs for an album include the gap at the end of the song file. At least the spacing between songs will be as the artist intends when the songs are assembled. Any releases in the iTunes store that are taken from albums will already have a gap at the end of the track that takes care of the album spacing. All mastering engineers will have already done that.
Gaps aside, what are the most common mixing errors you encounter from a mastering perspective?
The best advice I can give is have a relationship with your mastering engineer and see what he or she suggests before you finish your mixes! I offer a free listen evaluation of one song for anyone who's coming to me for mastering. I always suggest that you send the first song that you've mixed for the album for professional judgement. Regarding some of the major problems: getting the bass right is the biggest issue. The monitoring [some clients have] doesn't reveal the problems in the bass. There was a fantastic band from Australia, icecocoon, and the bass player used a drop-D-tuning. That's so difficult to mix! When it came to me, the bass guitar was completely missing from the mix. I asked them to send three stems: vocal, bass, bass drum, and the rest of the band. I did a combination of mixing and mastering for them. I found an EQ and process for the drop-D-bass that gave it just the right presence to hear all the notes correctly. It sounds so low that you can't hear the notes too well unless you EQ it just right. Software synthesizers are almost as difficult to deal with as drop-D-basses. With some synth sounds, there often aren't enough distortion harmonics to give a bass note definition. A good tool to enhance subharmonics is the Lowender plug-in by reFuse. It's my favorite subharmonic synthesizer, but be sure to mix or master with a wideband monitor system or you'll shoot yourself in the foot. A good tool to enhance upper bass harmonics is the UAD Precision Enhancer, or possibly the Waves MaxBass; but, again, be sure you have an accurate monitor.
In a recent issue of Stereophile, you recommended the PSI Audio AVAA C20 active bass trap as a revolutionary solution to low-end issues in a room. Why do you think it's a revolutionary device?
It seems to defy the laws of physics. It is a small trapezoidal box, about the size of a subwoofer, taking up a maximum power of perhaps 50 watts on sound level peaks with an average of 5 watts. It controls only the pressure peaks and deeps in the room from an amazing 15 Hz to 150 Hz, without artifacts and without overdamping the room. My system has moved from an A grade to an A+++ grade with the addition of three AVAA traps. I've never had such even, impacting, punchy, and clear bass. Measurements confirm that three AVAA traps are more effective than six 6-inch thick passive traps, and without the overdamping problems that the passive traps have. Unlike the AVAA, the passive traps have very little effect at extreme low frequencies and adversely affect the clarity and impact of the midrange and high frequencies.
When does overdamping actually start? What's a good relation between bass, mid, and high frequencies?
For best mid and high frequency performances, you should measure the so-called Schroeder curves in the room, where the rolloff of high frequencies should not be excessively compared to lows and mids. Many rooms are overdamped because the user tries to "fix" bass problems without regarding the overall effect. You can't beat the laws of physics.
As part of your mastering workflow, you developed the K-Stereo algorithm to extract the ambience of a signal. As a result, you could add more ambience of the original recording. The algorithm is used in a Weiss hardware processor, the Algorithmix K-Stereo and the UAD K-Stereo Ambience Recovery plug-ins. What made you come up with the idea?
The original "problem" was that my ears were telling me that I was getting recordings for mastering that sounded flat, or whose soundstage was too small, or even dimensionless. Some of this was due to mixing engineers not employing very good reverbs and/or delays in their mixing, or that they weren't taking advantage of their room. Maybe they were not properly dithering the output of their mixing DAW, or the DAW itself was technically causing a loss of depth that was fully preventable. Or all of the above! Fortunately, I was aware of several processes — as well as an article from 1970 — that got me thinking. It took me about a year to take an early version of the process to a higher quality. Then, one night, I woke up with an inspiration, which soon became the wide and deep settings that distinguish K-Stereo from any previous mastering approaches to the depth and width problem. There is little or no coloration with the K-Stereo compared to many other attempts at width enhancement. If you want to get better depth in mixing, there really are only a very few artificial reverbs that pass the dimension test. My very short list, in alphabetical order: Bricasti M7, EMT 250 and its UAD replica, Flux Ircam Spat, TC Electronic VSS4 and VSS 6.1. I haven't heard the Quantec Yardstick, but users report that it has similar power. Convolution reverb samples of these units need not apply, because they do not capture all the dimension of the unit — largely just the tone. Most people listen for the tone and ignore the dimension, which is a very important part of a reverb's sound.
How do you judge the dimension of a reverb?
I think the best way to judge the depth of a reverb is by a trained ear, with a good monitoring system that does not have diffraction, in a reflection-free zone. And there are many "gotchas." I'm a big fan of the Flux Spat, but if it is used improperly it can deteriorate depth instead of enhance it. It requires trained ears to use it well. One of my favorite reverbs of all time is the EMT 250, and its emulation in the UAD has a lot of the original device's artificial depth, even though it is mono in/stereo out.
With K-Stereo, where do you think it works best, and what are the limits of the application?
The K-Stereo Processor can, to some extent, help the depth and dimension of one of the lesser-quality reverbs that a mix engineer may have used. Or it can put the last polish on the mix engineer's use of even the best reverbs. It's important for me to say that "too much of a good thing" is just as bad as "not enough." And that everyone trying the K-Stereo goes through an initial process of using too much because it sounds nice, but may not initially recognize that there are always downsides to every process. Just as when using reverb itself, when we are mixing, we all tend to start by using a bit too much, then backing it off. Also note that the K-Stereo can improve the focus and localization in a mix. But be careful: when used in excess, it can soften the focus and make important instruments, like the lead vocal, pull back in the mix. But, unlike so many other things which mastering engineers try — like M/S [mid-side] processing, which is powerful but also screws up the mix if overused — the K-Stereo is more invisible and subtle. A little bit goes a long way. Or don't use any, if the recording doesn't call for it! Use your ears! And to avoid any misunderstanding: it's not possible to reduce ambience with K-Stereo.





